
algo de compression
Cette présentation se donne comme objectif d'expliquer le principe de base ,d'un algorithme de compression de la manière la plus simple possible. Le volet mathématique est mis volontairement de côté. Partant du constat que pour une taille donnée de fichiers ,l'entropie d'une séquence est inversement proportionnelle à sa longueur. Dit différemment : si la taille d'un fichier est plus petite que toutes les combinaisons possibles d'une chaîne donnée,il y a de quoi à faire. voilà fin du volet mathématique :-) Donc si j'ai 2 données consécutives lues dans un flux ou un fichier que je représente sous une forme graphique ou dans un tableau ici, par exemple le couple [11,20] ou [20,11]
Puis maintenant,si je suppose que mon flux ou mon fichier ne contiennent que du texte en minuscule ce qui donne une zone 97 à 122 si j'en crois la table ascii, donc j'obteins la representation suivante
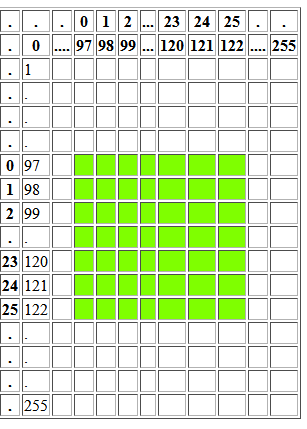
On se rend bien compte que je n'ai pas besoin de 8 bits pour couvrir l'espace, mais de 5 bits puisque 26 en binaire cela donne 11010, donc tous couples de données de cette zone au lieu d'être codés sur 2*8 bits se retrouvent codés par 2* 5 bits auquel je rajoute un bit qui indique si le plus grand est lu en premier ou pas, ce qui fait 2*8=16 bits devient après compression 2*5+1=11 bits donc toutes paires de cette zone engendrent un gain de 5 bits par contre cela ne suffit pas
puisque je suppose que tout le fichier n'est pas dans cette zone, donc je dois rajouter un en-tête que l'on peut imaginer comme
Données compressées
1 bit pour indiquer que les données sont codées
15 bits pour donner la quantité de données codées
8 bits pour indiquer le numéro de la grille (c'est nettement mieux quand il y en a plusieurs)
Données non codées
1 bit pour indiquer que les données ne sont pas codées
23 bits pour indiquer la quantité de données à recopier telle quelle
Donc l'on a un en-tête sur 24 bits ce qui implique que ce codage ne sera efficace que si le système compresse plus de 2*24 bits dans notre cas, il faudra plus de 9 paires ou à peu près 4 mots pour que je commence à engendrer un gain de 5 bits par paire Un exemple qui marche avec un en-tête légèrement différent plusieurs grilles [ (0.255),(n*0,n*63) ] avec n =1 à 5 si il y a quelques amateurs, un exemple de code sous gpl ici avec la muse de tous les algos de compression. bon bref ,cette implémentation n'a pour vocation qu'à servir de test ou d'amusement, dit différemment c'est long, très long et c'est normal
Structure de l'en-tête
2^15 =0 donnée non codée
2^14...2^0 quantité d'octets à lire et à recopier sans décompression
2^15=1 donnée codée
2^13...2^3 quantité d'octets à lire et à décompresser
2^2...2^0 nombre de décalage d'un pas de 63
javac Main.java
Note: Some input files use unchecked or unsafe operations.
Note: Recompile with -Xlint:unchecked for details.
java Main c lena_std.tif
compression
49 15 49 15 49 15 49 15 49 15 ...
java Main d lena_std.tif.ar
decompression
ls -l lena*
-rw------- 1 remy remy 786572 2009-01-16 16:23 lena_std.tif
-rw-r--r-- 1 remy remy 777629 2009-02-23 15:03 lena_std.tif.ar
les aventages du système
Cet algorithme permet de faire de la compression à la volée donc particulièrement bien adapté au flux puisqu'il n'y a pas de calcul de fréquence et peut trés bien être adapté à un contexte spécifique puisqu'une même zone peut ne pas être continue ou d'un seul bloc ,multi format puisqu'il y a forcément plusieurs grilles.à ma connaissance, cette approche n'est pas utilisée pour faire de la compression.De là à penser que cela soit nouveau ? je ne franchis pas le pas, puisque je vous laisse à vos recherches d'antériorité pour ceux que cela intéressent
un lien sur les algos les plus connus et utilisés histoire de se faire une idée sur l'antériorité merci wikipedia http://fr.wikipedia.org/wiki/Compression_de_données
dans tous les cas merci pour votre attention
par contre je suis toujours intéressé par un quelconque retour constructif de préférence.